Data Engineering: ETL/ELT vs ETLT vs ETLT++
Материал на основе научной статьи о гибридном паттерне ETLT и его развитии в сторону ETLT++.
Igor Gorin · June 2026
На основе статьи by Chiara Rucco, Motaz Saad, Antonella Longo. Original article
Введение
В дата инженерии паттерны проектирования загрузок данных относятся к стандартизированным методам, которые включают процессы ETL/ELT, конвейеры передачи данных и управление потоками данных.
В то же время современный стек обработки данных сталкивается с некоторыми системными проблемами:
-
Зоопарк инструментов и их взаимодействие между собой.
-
Операционная сложность при организации и управлении.
-
Постоянные проблемы в качестве данных, которые отнимают до 80% времени инженеров.
-
Отсутствие метаданных и отсутвие data lineage, препятствующие управлению.
ETL и ELT
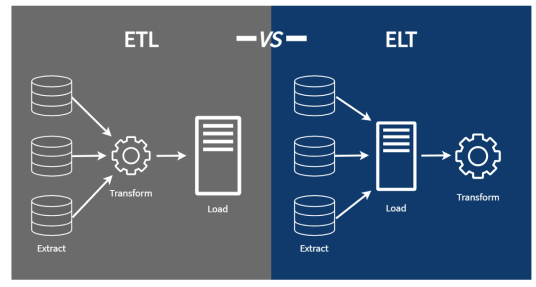
Согласно рисунку 1 методология ETL/ELT, предлагают трансформацию данных либо перед загрузкой, либо после. Традиционный ETL, извлекая данные, применяет бизнес-логику во время преобразования. ELT меняет эту последовательность, загружая сырые данные непосредственно в хранилище, а преобразование выполняет уже внутри хранилища данных. ELT подход значительно сокращает нагрузку на систему источник и инструмент интеграции, позволяет итеративно совершенствовать логику преобразования и поддерживает более гибкую эволюцию схемы.
Но несмотря на эти преимущества, ELT имеет и минусы:
-
отсутствие предварительной проверки качества данных, которое может привести к распространению некорректных данных,
-
процессы ELT, при загрузке без предварительной фильтрации, загружают большие объемы ненужных данных и нагружают пропускной канал.
Золотая середина
На практике инженеры смешивают оба подхода в одном потоке в зависимости от ситуации и личного опыта. Гибридный шаблон ETLT применяется постоянно, но стандартизированных определений или устоявшейся передовой практики для ETLT нет.
Классические процессы ETL и ELT являются зрелым эталонными процессами. В то же время паттерн ETLT, остается недостаточно развитым. Если пойти дальше, то простого изменения методов ELT в ETLT будет недостаточно. Нужны шаблоны, которые добавляют проверки качества данных, обеспечивают возможность аудита, управления и повышения производительности разработчиков. Появляется следующее поколение паттернов с суффиксом “++”, то есть ETLT++.
Тем более динамичный характер требований к данным в сочетании с быстрым появлением новых технологий требует постоянной эволюции и адаптации существующих шаблонов.
1. Шаблоны проектирования ETLT
Во многих сценариях основная трудность заключается в качестве входящих данных. Очистка и валидация на раннем этапе являются критически важными.
Шаблон ETLT обеспечивает качество данных на начальном этапе преобразования, обозначаемом T1, рисунок - 2, где применяются очистка, проверка и нормализация для обеспечения согласованности и сопоставления данных. Только после этого контроля данные переходят на этап загрузки в хранилище. Затем на втором этапе преобразования T2, применяются бизнес-правила трансформации, обогащение и формирование схемы для витрин.
Вынеся проблемы качества данных в T1, ETLT гарантирует, что последующие бизнес-преобразования не будут падать с ошибкой или загрязнены некачественными входными данными.
Так же такая схема позволяет выполнять детерминированное воспроизведение T2 без повторного извлечения и повторной очистки исходных данных.

ETLT особенно хорош, когда качество данных не само собой разумеющееся. В системах, которые объединяют данные из различных источников, или где надежность источника низкая. Паттерн гарантирует, ошибочные записи будут обнаружены до того, как они попадут в центральное хранилище. Это делает ETLT ценным шаблоном в системах со строгими требованиями к данным, например финансовой отчетности или медицине.
Однако, несмотря на свои сильные стороны, шаблон не подразумевает обязательного исполнения дата контрактов, возможности детерминированного воспроизведения, сбора данных о происхождении, мониторинге и показателей качества данных
2. ETLT++
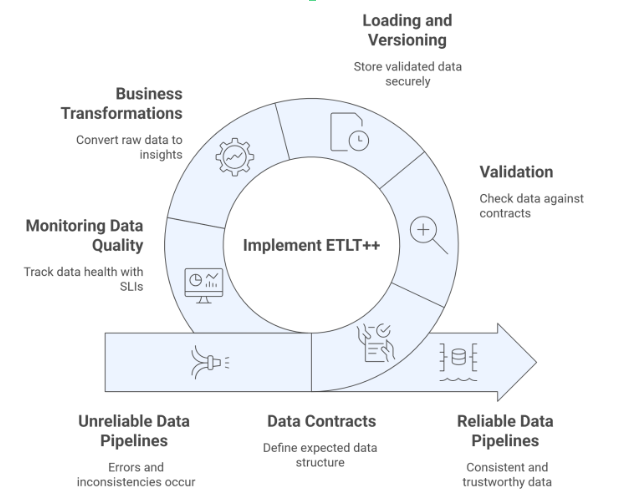
В то время как ETLT отделяет проверку качества данных от бизнес-логики, ETLT++ добавляет расширенные контрольные метрики и функции. Новизна заключается в переходе от ситуативных гибридных рабочих процессов к формально структурированному паттерну проектирования, который гарантирует воспроизводимость, мониторинг и непрерывное обеспечение качества.
Определяется ETLT++ как последовательность связанных этапов:
P = ⟨E, C, T1 , L, T2 , O⟩
где:
• E (Extract from Sources): Сырые данные
• C (Data Contract Loading): Дата контракт. Объект правил в формате JSON или другом виде. Контракт указывает на правила, такие как обязательные поля, диапазоны значений, форматы и определяет строгость правил (hard vs. Soft).
• T1 (Validation and Cleaning): Применение контракта:
– При нарушении hard rule запись помещается в карантин, при нарушении soft-rule логируется предупреждение.
– Проверка на уровне пакета останавливает всю загрузку, если возникают какие-либо hard violations.
• L (Load into Versioned Raw Storage): Хранение проверенных записей в raw zone, которая сохраняет каждую загрузку данных и временную метку.
• T2 (Business Logic and Transformation): Операции, которые преобразуют сырые данные в структурированные, готовые к анализу наборы данных, например, агрегации, обогащения или отслеживание исторических изменений, с использованием многократно используемых шаблонов SQL трансформации.
• O (Outputs): Публикация подготовленных наборов данных для последующих потребителей.
2.1 Data Contracts (C)
На практике одна из наиболее критических проблем в инженерии данных заключается в том, что сырые данные, поступающие из множества гетерогенных источников, часто являются неполными или противоречивыми. Без механизма блокировки такие данные попадают в хранилище и портят последующие слои данных. Одна ошибка на стороне источника (например, отрицательное значение оплаты счета), распространившись без проверки в финансовые дашборды, исказит итоговые цифры.
В отличие от ETLT, где механизмы проверки могут быть неявными или от случая к случаю, ETLT++ обозначает использование проверок данных, определенных в data contracts, как обязательные и явные средства защиты. Data contract — статическая спецификация правил, которой должен соответствовать каждый набор данных перед входом в конвейер.
Data contracts не являются чем-то новым, они представляют собой хорошо зарекомендовавший себя механизм управления данными. Однако в существующих системах они часто являются необязательными или внедряются непоследовательно. В ETLT++ наоборот, data contracts строго обязателен.
Правила могут быть классифицированы как hard или soft. Hard rules — это строгие ограничения: в случае их нарушения данные не должны поступать в конвейер. Soft rules носят рекомендательный характер: нарушения вызывают предупреждения, но не блокируют обработку. Это различие обеспечивает гибкость.
2.2 Validation: Enforcing Contracts (T1)
Обязательный этап - Валидация, которую применяет data contracts.
Этапы валидации:
-
Извлечение контракта: Загрузка JSON-контракта из реестра метаданных.
-
Уровень записей. Для каждой записи r в поступающем пакете:
Для каждого hard rule i и каждой записи r вычисляется индикатор нарушения
v_{i, r} =1, если запись r нарушает правило i;
0, если запись r не нарушает правило i.
• Если любое (i, r) = 1, то пометить запись r как находящуюся в карантине. Валидацию продолжить.
• Если нарушено soft rule, залогировать предупреждение, но разрешить продолжение обработки.
-
Уровень пакета. Вычислить общее количество hard violations:
Если V > 0, остановить загрузку всего пакета и пометить его ошибочным; в противном случае перейти к загрузке.
Пример: Предположим, мы получаем пакет из пяти записей клиентов:
| client_id | Amount | Status | reason | |
|---|---|---|---|---|
| 1001 | 50 | [email protected] | Pass | Validated successfully |
| 1002 | -20 | [email protected] | Quarantined | Hard rule violated: negative amount |
| 1003 | 30 | (missing) | Pass | Soft rule violated: missing email |
| 1004 | 0 | [email protected] | Pass | Validated successfully |
| 1005 | 10 | [email protected] | Pass | Validated successfully |
Только запись 1002 нарушает hard rule и помещается в карантин. Поскольку V = 1, загрузка пакета останавливается до разрешения проблемы.
Эффект от комбинации контракта и валидации заключается в том, что конвейеры становятся предсказуемыми: невалидные записи останавливаются на границе, предупреждения логируются для последующего контроля, и только заслуживающие доверия данные попадают в хранилище.
Иными словами, в ETLT++ качество данных является не опциональной фичей, а обязательным свойством надежной современной платформы данных.
2.3 Loading and Versioning (L)
Во многих конвейерах данных фаза загрузки рассматривается как простая операция типа «черный ящик», при которой данные сохраняются в базе данных или озере. Это чрезмерное упрощение создает две повторяющиеся проблемы. Во-первых, многие используемые хранилища данных не поддерживают версионирование нативно, что означает, что после перезаписи данных прежние состояния теряются навсегда. Это делает невозможным реконструкцию того, как набор данных выглядел в определенный момент времени. Во-вторых, даже когда доступны современные табличные форматы, такие как Delta Lake, Apache Iceberg или Hudi, функции версионирования часто настроены плохо или игнорируются. В обоих случаях последствие одинаково: команды не могут выполнить time-travel, провести аудит.
В результате становится невозможным ответить на такие вопросы, как: «Как выглядели данные на прошлой неделе, когда создавался отчет?» или « Какие записи изменились с момента последней проверки?».
Поэтому ETLT++ рассматривает версионированную загрузку в режиме append-only как обязательную. Данные сохраняются неизменяемыми: после вставки записи никогда не удаляются и не изменяются, а только добавляются. Это устраняет хрупкость ситуативных подходов и гарантирует, что аналитики, аудиторы и инженеры всегда могут совершить «путешествие во времени» по набору данных для воспроизведения и валидации.
Эти свойства обеспечивает надежность, прозрачность и возможность аудита конвейеров ETLT++, что выносит ETL/ELT на совершенно новый качественный уровень.
3. Мониторинг и обеспечение качества данных
Даже при наличии строгих контрактов, валидации и стандартизированных трансформаций конвейеры могут генерировать ошибки, задержки или несоответствия из-за сбоев на стороне источников, отсутствующих данных или человеческого фактора.
ETLT++ предлагает паттерн проектирования для мониторинга и обеспечения качества данных. Первый шаг заключается в определении Service Level Indicators (SLIs), которые отражают основные аспекты качества, как: freshness, completeness, accuracy и contract adherence. ETLT++ предлагает эти SLIs как обязательные архитектурные компоненты.
Freshness — эта метрика оценивает, насколько актуальными являются данные. Например, если система ожидает ежедневные данные о продажах, но последний пакет был получен три дня назад, SLI для freshness просигнализирует о проблеме.
Freshness = Current Time − Timestamp of Latest Batch
Completeness — оценивает, все ли ожидаемые записи или поля были получены.
Completeness = Number of Records Received / Number of Records Expected
Низкий показатель completeness указывает на отсутствующие или частичные данные.
Accuracy — Accuracy измеряет, насколько хорошо данные соответствуют правилам валидации, определенным в data contract. Например, если возраст, цены или даты выходят за пределы ожидаемых диапазонов, accuracy снижается.
Accuracy = 1 − Invalid_records / Total Number of Records
Поддержание высокой accuracy гарантирует, что данные, используемые для отчетности и принятия решений, достаточны.
Contract Adherence — Этот индикатор проверяет, соблюдает ли каждый поступающий пакет согласованный data contract, включая как hard rules (которые должны быть выполнены), так и soft rules (которые могут генерировать предупреждения). Contract adherence может мониториться как процент пакетов, полностью соответствующих контракту:
Contract Adherence = Number of Compliant Batches / Total Batches
Отслеживание contract adherence обеспечивает видимость того, поставляют ли вышестоящие системы данные в ожидаемом формате и структуре.
Как только SLIs определены, конвейер оснащается инструментами для автоматического сбора метаданных и статистики для каждого пакета, включая временные метки, количество записей и ошибки валидации. Показатели качества вычисляются для каждого набора данных и сравниваются с заранее определенными пороговыми значениями. Если какая-либо метрика падает ниже приемлемого уровня, автоматические оповещения уведомляют инженеров, или запускаются корректирующие действия, такие как повторная загрузка, перерасчет. Исторические логи SLI сохраняются для аудита и анализа трендов. Циклический анализ логов SLI непрерывно улучшает качество данных с течением времени.
Пример:
-
Freshness: Проверить, что последний пакет пришел в пределах 24 часов.
-
Completeness: Подтвердить, что все ожидаемые значения и поля присутствуют.
-
Accuracy: Суммы транзакций неотрицательны и находятся в ожидаемых диапазонах.
-
Contract Adherence: Проверить, что схема соответствует согласованному определению и обязательные поля присутствуют.
Внедрение качества данных непосредственно в конвейер как многократно используемый компонент на основе паттернов ETLT++ превращает обеспечение качества из разовой ручной задачи в активную, автоматизированную и масштабируемую практику. Этот подход защищает процесс принятия решений, поддерживает доверие к аналитике и обеспечивает надежную, воспроизводимую обработку корпоративных данных.
Заключение
ETLT++ превращает ETLT в надежный паттерн при наличии:
• Data Contracts
• Versioned raw storage: immutability, traceability, and reproducibility by design.
• Rewindable business logic: deterministic transformations that can be reapplied.
• Continuous monitoring: SLIs and SLOs integrated into the pipeline fabric.
Эти свойства обеспечивают надежность, прозрачность и возможность аудита конвейеров ETLT++, что выносит ETL/ELT на совершенно новый качественный уровень.
Источники
Rucco, C., Saad, M., Longo, A. “Formalizing ETLT and ELTL Design Patterns and Proposing Enhanced Variants: A Systematic Framework for Modern Data Engineering.” arXiv, November 2025. Original article